
Performance Improvements in JDK 24
Claes Redestad, Per-Ake Minborg on March 19, 2025This article summarizes the performance improvements made in JDK 24 compared to JDK 23 by highlighting some of the most noteworthy progressions. In order to facilitate traceability, the improvements are listed per issue (or per umbrella issue explained in the note below) as entered into the official JDK Bug System. Let’s check them all out!
“Umbrella issues” are parent issues that consist of a number of sub-issues which are related to each other. Keeping related issues together is great when working with larger tasks that could affect many distinct parts of the JDK.
Core Libraries
JDK-8340821 Umbrella: Improve FFM Bulk Operations
This enhancement is a part of a series aimed at improving the performance of the Foreign Function & Memory API (FFM API) that was finalized back in Java 22. Here are all the issues under this umbrella:
- JDK-8338967 Improve Performance for MemorySegment::fill
- JDK-8338591 Improve performance of MemorySegment::copy
- JDK-8339531 Improve performance of MemorySegment::mismatch
- JDK-8339527 Adjust threshold for MemorySegment::fill native invocation
In short, these bulk operations on segments were previously made via Unsafe methods which require a transition from Java to native code. Many times, native code is faster than Java code once the price of transition is paid. However, for a smaller segment, it has become evident that transitioning to native code is not worth the price.
Here is an example on how to create a small segment filled with 0xFF (using fill method`):
MemorySegment segment = arena.allocate(8).fill((byte)0xFF);
The idea behind all the improvements in this series is to check if the participating segment(s) are “small” and if so, perform the bulk operation using pure Java code rather than transitioning to native code. The “small” size partition threshold (which is always a power of two) is set to a reasonable default value (usually 2^6 = 64 bytes). Via three new system properties, the partition thresholds can be set to bespoke values. In the example below, we have increased all the thresholds levels to 212 = 4,096 bytes via command line parameters:
-Djava.lang.foreign.native.threshold.power.fill=12-Djava.lang.foreign.native.threshold.power.copy=12-Djava.lang.foreign.native.threshold.power.mismatch=12
By setting the threshold power values to zero, the old Unsafe-only path will be taken and consequently, these enhancements will be disabled.
Currently, there is no intrinsic implementation for MemorySegment::fill on AArch64. Because of this, the default threshold is much higher on this particular platform (i.e. 210 = 1,024 bytes).
Here is a chart of the MemorySegment::fill latencies for various smaller segment sizes on the Linux X64 platform (Lower is Better):
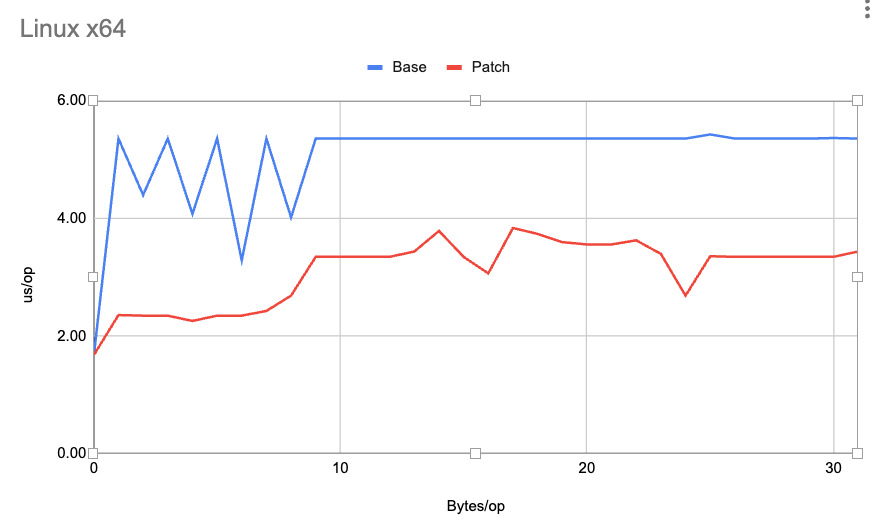
As can be seen, the “Patch” (which represents the improvement) is much faster than the “Base” (which represents the old Java-23 branch). Similar characteristics are exhibited on all the other supported platforms and for the other bulk operations MemorySegment::copy and MemorySegment::mismatch. The JDK 24 pull requests themselves contain a much more comprehensive set of benchmarks and charts that outline individual performance metrics. Here is the PR for fill method.
Looking more into the details of the implementation, we see that the new bulk operations have been moved into a separate class called jdk.internal.foreign.SegmentBulkOperation and that the operations are performed in units of first long operations then int, short , and byte operations, if necessary. Here is an excerpt from SegmentBulkOperations::fill:
if (dst.length < NATIVE_THRESHOLD_FILL) {
// Handle smaller segments directly without transitioning to native code
final long u = Byte.toUnsignedLong(value);
final long longValue = u << 56 | u << 48 | u << 40 | u << 32 | u << 24 | u << 16 | u << 8 | u;
int offset = 0;
// 0...0X...X000
final int limit = (int) (dst.length & (NATIVE_THRESHOLD_FILL - 8));
for (; offset < limit; offset += 8) {
SCOPED_MEMORY_ACCESS.putLongUnaligned(dst.sessionImpl(), dst.unsafeGetBase(), dst.unsafeGetOffset() + offset, longValue, !Architecture.isLittleEndian());
}
int remaining = (int) dst.length - limit;
// 0...0X00
if (remaining >= 4) {
SCOPED_MEMORY_ACCESS.putIntUnaligned(dst.sessionImpl(), dst.unsafeGetBase(), dst.unsafeGetOffset() + offset, (int) longValue, !Architecture.isLittleEndian());
offset += 4;
remaining -= 4;
}
// 0...00X0
if (remaining >= 2) {
SCOPED_MEMORY_ACCESS.putShortUnaligned(dst.sessionImpl(), dst.unsafeGetBase(), dst.unsafeGetOffset() + offset, (short) longValue, !Architecture.isLittleEndian());
offset += 2;
remaining -= 2;
}
// 0...000X
if (remaining == 1) {
SCOPED_MEMORY_ACCESS.putByte(dst.sessionImpl(), dst.unsafeGetBase(), dst.unsafeGetOffset() + offset, value);
}
// We have now fully handled 0...0X...XXXX
}
We are looking forward to improving the JIT’s C2 auto-vectorization (which is not the same as the incubating Vector API) so that the code above could be expressed much simpler and would be even more performant in the future.
JDK-8336856 Efficient Hidden Class-Based String Concatenation Strategy
By exploiting hidden classes - which allow bootstrap libraries to safely define classes with access to internals - we now generate String concatenation expressions in a much more efficient way.
Instead of generating complex MethodHandle combinators we can build direct, hidden — yet unloadable — classes which can be cached and reused by different callers.
This avoids a lot of work generating intermediate MethodHandle instances which were never directly invoked - reducing number of classes and other runtime overheads. On targeted tests which bootstrap and use a reasonably realistic set of String concatenation expressions we see 40% improvements on startup, and about half as much class generation at runtime after integration of this enhancement.
Peak performance and throughput performance remain neutral for typical applications - but applications should now get there faster and with less effort.
JDK-8333867 SHA3 Performance Can be Improved
By reducing conversions back and forth between a byte array and a long array, various SHA3 algorithms have been improved by up to 27% — depending on platform and algorithm used. Related work on an AArch64 intrinsic might broaden the set of platforms that sees similar improvements, as seen in JDK-8337666.
JDK-8338542 Umbrella - Reduce Startup Overhead Associated with Migration to ClassFile API
The ClassFile API is going final in JDK 24, but is already used internally in some JDK library code since JDK 23. For JDK 24 almost every mechanism that generates bytecode at runtime in the JDK will use it, typically replacing the ASM third-party library. Once the ClassFile API is adopted by third-party libraries, the migration to a new JDK version will be much smoother as applications can rely on the JDK’s own byte code generation, which will always be kept current and up to date.
However, this transition hasn’t been entirely pain-free. Adopting the ClassFile API has had a slight negative impact on startup, warmup and some footprint measures compared to the low-level ASM library used before.
A lot of work has been done in JDK 24 to identify and resolve regressions. Some rough edges remain, but on a few startup tests we already surpass JDK 23 numbers. And as we’ve been working through the most glaring startup issues results on other benchmarks have been steadily improving. E.g, a 40-50% improvement on ClassfileBenchmark.parse.
Runtime
JEP 491 Synchronize Virtual Threads without Pinning
Previously, virtual threads were pinned to their carrier thread during synchronization. This JEP improves the scalability of Java code that uses synchronized methods and statements by arranging for virtual threads that block in such constructs to release their underlying carrier threads for use by other virtual threads. This will eliminate nearly all cases of virtual threads being pinned to carrier threads.
As a result, virtual threads will run much faster for certain workloads and the recommendation to use locks instead of synchronization for virtual threads can be lifted.
JDK-8180450 Better Scaling for secondary_super_cache
The secondary super cache, SSC, is (or was) an optimization to speed up certain type queries, including some instanceof expressions, by means of a one-element cache on the class containing a pointer to the super type. On certain workloads this cache may be routinely invalidated and replaced, and if the workload is multithreaded (running across many cores or even multiple hardware sockets) then that can lead to pretty severe scalability issues from cache line ping-ponging.
The PR foregoes the 1-element super cache for C2-compiled code entirely in favor of a hash table lookup. A hash table has a small overhead (1-2 cycles) in the “happy”, positive case, but is much faster on negative lookups. And most importantly since the hash tables is not altered by concurrent threads while running the application, this completely avoids the potentially massive slowdowns on multithreaded applications.
For the most common platforms (Aarch64 and x64) these enhancement landed already in JDK 23, but it is worth a mention for JDK 24 as we now see ports land for all OpenJDK platforms:
- JDK-8332587 RISC-V: secondary_super_cache does not scale well
- JDK-8331126 s390x: secondary_super_cache does not scale well
- JDK-8331117 PPC64: secondary_super_cache does not scale well
JDK-8320448 Accelerate IndexOf Using AVX2
This change improves the performance of String::indexOf about 1.3x for x64 platforms with AVX2 support. The 1.3x speedup factor was calculated as an average of a small number of benchmark types.
In short, intrinsic code has been added for the String::indexOf method where the compiler can emit specialized SIMD machine code instructions capable of handling larger data units at the same time. This results in higher performance, especially for larger strings.
JDK-8322295 JEP 475: Late Barrier Expansion for G1
This enhancement simplifies the implementation of the G1 garbage collector’s barriers, which record information about application memory accesses, by shifting their expansion from early in the C2 JIT’s compilation pipeline to later. An observable benefit of this is a significant reduction in the overheads of C2 compilation, reducing time and memory usage of the JVM when starting and warming up applications. Similar work was implemented for ZGC already in JDK 14 since it was needed for correctness under high concurrency.
JEP 483: Ahead-of-Time Class Loading & Linking
JDK 24 introduces the concept of an ahead-of-time cache which incrementally improves upon the CDS technology that has been a part of the JDK since 2004. This AOT cache can now store not only a pre-parsed class state like CDS does, but also the state of classes after loading and linking them. This requires capturing more information during a training run, and improves incrementally on the baseline.
| HelloStream | PetClinic | |
|---|---|---|
| JDK 23 | 0.031 | 4.486 |
| AOT cache, no loading or linking | 0.027 (+13%) | 3.008 (+33%) |
| AOT cache, with loading and linking | 0.018 (+42%) | 2.604 (+42%) |
JEP 483 is a first deliverable of the Project Leyden whose goal it is to improve startup, warmup and footprint of Java programs while staying true to the dynamic nature of the Java language.
Upcoming JEPs aim to improve the training workflow introduced in JEP 483 to a streamlined one-step process, add profiling data and AOT’d code to the ahead-of-time cache, and much more.
JDK-8294992 JEP 450: 8-byte Object Headers (Experimental)
This experimental enhancement reduces the size of the object headers in the HotSpot JVM from between 96 and 128 bits down to 64 bits on 64-bit architectures. This will reduce heap size, improve deployment density, and increase data locality.
Early experiments indicate one can expect a reduction in memory consumption from 10% to 20% for common workloads. Throughput wise, the impact depends on the workload. There is a report of performance testing with JEP 450 that shows promising result for SPECjbb2015 (4-7% gains, depending on tuning). Other workloads show no change in performance at all (which is still good if memory usage was reduced at the same time). Additional improvements are being worked on to improve performance and once the experimental state is dropped, it is likely we will see even better benchmark results across the board.
Ports
RISC-V Improvements
A lot of effort has been put into leveling the field for RISC-V based platforms. We’d like to give a special thanks to the participants in this area for working with this even though RISC-V is not widely used (yet), and thus paving the way for true open-source platforms:
- JDK-8334554 RISC-V: verify & fix perf of string comparison
- JDK-8334397 RISC-V: verify perf of ReverseBytesS/US
- JDK-8334396 RISC-V: verify & fix perf of ReverseBytesI/L
- JDK-8317721 RISC-V: Implement CRC32 intrinsic
- JDK-8317720 RISC-V: Implement Adler32 intrinsic
Other Improvements
Below you can find additional performance issues not further elaborated on in this article, also addressed in JDK 24, but which may nevertheless play an important role in keeping Java performant:
- JDK-8323079 Regression of -5% to -11% with SPECjvm2008-MonteCarlo after JDK-8319451
- JDK-8323385 Performance regression with runtime/AppCDS/applications/jetty/* tests after JDK-8324241
Conclusions and Next Steps
Phew! That was a lot. All the changes we listed in this article were possible thanks to the OpenJDK community that tirelessly works on improving Java’s performance.
The next step is actually up to you, dear reader! Download JDK 24 and take it for a spin. How much faster is your application under this version compared to the version you are currently using? Did you notice anything that can be improved? Get involved in the community and raise an issue, submit a PR, and participate in the mailing list discussions.
There are also some videos on inside.java that talks about performance improvements in Java 24:
- Java 24, Faster Than Ever! by Per Minborg
- Java 24, Performance Improvements and Deprecations - Inside Java Newscast #82 by Nicolai Parlog and Billy Korando
Some of us are already working on new improvements slated for the upcoming JDK 25 release, and we are so much looking forward to writing a new performance article once JDK 25 is released.
Until then… Stay on the fast path!